Streamline Airflow's SparkSubmitOperator
In Airflow deployments that use (Py)Spark to crunch data, you might encounter the
SparkSubmitOperator
as operator of choice. It is a wrapper around spark-submit. By using this operator you
can specify a target script that will be executed by spark-submit. In most cases this
is a Python script executing PySpark code (see full code
here):
# dags/customer_ingestion.py
from airflow.models import DAG
from airflow.providers.apache.spark.operators.spark_submit import SparkSubmitOperator
with DAG(**vanilla_dag_conf) as vanilla_dag:
t = SparkSubmitOperator(
task_id="t1",
application="jobs/start.py",
application_args=["data_ingest.ingestion1:main"],
env_vars={"LOG_LEVEL": "DEBUG"},
conn_id="spark_local",
)
This setup is sufficient in most cases. Especially in the beginning and in “The Internet”. Many tutorials and articles outline this as the way to go, giving me the impression that a large percentage of Airflow documentation is created by people that just started using Airflow.
Still, this basic setup comes in many different flavours. Obvious differences you can find in
- What is supplied as parameters
- How DAGs and tasks are organised
- How the task script is structured
- How external libraries are handled
- How the DAGs, task scripts and logic are distributed
Project organisation
The answer to the above questions depends on the project size and setup. If your project reaches a certain size, it makes sense to group your code as Python package. A Python package is easier to test and use in different environments. Additionally, it can be decoupled from Airflow. A typical project layout:
.
├── Makefile
├── dags
│ └── customer_ingestion.py
├── jobs
│ └── start.py
├── pyproject.toml
├── src
│ └── data_ingest
│ └── ingestion1.py
├── dags_tests
└── tests
Execution Path
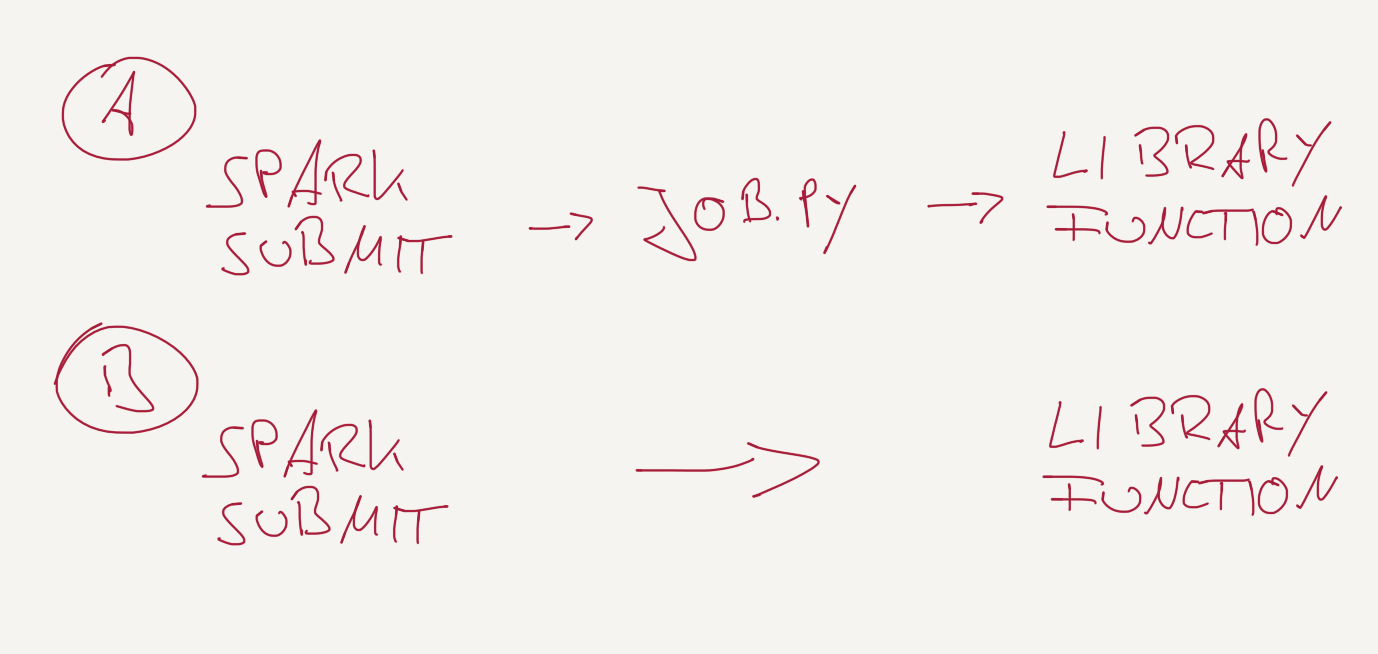 Figure 1: (A) The standard path of execution for Airflow tasks (B) A
shortcut between the
Figure 1: (A) The standard path of execution for Airflow tasks (B) A
shortcut between the SparkSubmitOperator and the library function using a generic
start script.
Still, you need an interface between the Airflow operators and your library code. Often simple Python scripts are used as proxies. They take the supplied commandline args and pass them on to an imported function from a Python package (fig. 1A).
If you have a lot of DAGs, you will end up with many, mostly redundant, proxy scripts of the form:
# jobs/my_job.py
import logging
from data_ingest.ingestion1 import main
logger = logging.getLogger(__name__)
if __name__ == "__main__":
logger.info("Some random message that nobody reads")
# alternatively you can also parse sys.argv here
main()
Luckily, the Python import system is very flexible and allows dynamic imports. This functionality allows the creation of a generic start script, a shortcut (fig. 1B):
# jobs/start.py
import importlib
import logging
import sys
import os
logger = logging.getLogger(__name__)
def main():
(prog, jobname, *rest) = sys.argv # (1)
sys.argv = [prog, *rest] # (2)
(mod_name, fn_name) = jobname.split(":", maxsplit=1) # (3)
logger.info(f"Starting job {jobname}")
mod = importlib.import_module(mod_name) # (4)
fn = getattr(mod, fn_name) # (5)
fn() # (6)
if __name__ == "__main__":
_init_logging_system()
main()
(details are omitted for brevity, full code here)
So what happens here?
sys.argvis split into the script name, thejobnameand the remaining arguments.- We repack the script name and arguments into
sys.argvso thatstart.pyis transparent for the target function. - The
jobnameis a combination of target module and function name. We split the job name into the module and function name. The syntax follows the one for creating executable scripts in pyproject.toml, so themainfunction indata_ingest.ingestion1would be specified asdata_ingest.ingestion1:main. - We import the module
- We get the function from the imported module
- We execute the function
There is only one question remaining: how do you call this generic script best?
Approach 1: a wrapper function disguised as class
# dags/customer_ingestion.py
def MySparkSubmitOperator(application="", application_args=None, *args, **kwargs):
if isinstance(application, str) and re.search(r"^\w+(?:\.\w+)*:\w+$", application):
application_args = [application] + (application_args or [])
application = "jobs/start.py"
return SparkSubmitOperator(
*args,
application=str(application),
application_args=application_args,
**kwargs,
)
with DAG(**dag_conf_msso) as dag_msso:
t = MySparkSubmitOperator(
task_id="t1",
application="data_ingest.ingestion1:main",
env_vars={"LOG_LEVEL": "DEBUG"},
conn_id="spark_local",
)
Approach 2: a custom function that is adapted to your needs
# dags/customer_ingestion.py
def create_spark_task(task_id: str, app: Union[str, Path], *, args: Optional[List[str]] = None, **kwargs):
if isinstance(app, str) and re.search(r"^\w+(?:\.\w+)*:\w+$", app):
args = [app] + (args or [])
app = "jobs/start.py"
return SparkSubmitOperator(
application=str(app),
application_args=args,
task_id=task_id,
**kwargs,
)
with DAG(**dag_conf_cst) as dag_cst:
t = create_spark_task(
"t1",
"data_ingest.ingestion1:main",
env_vars={"LOG_LEVEL": "DEBUG"},
conn_id="spark_local",
)
The full code you can find here
It makes sense to move the helper functions into a util.py module and use them
throughout your DAGs.
Good luck with your Airflow setup!
Have fun!